Sailor: Automated ML Training System for the Cloud
The Challenge
Training large-scale LLMs in the cloud is expensive and complex. Loads of systems struggle with slow fault tolerance mechanisms. It is difficult to find optimal resource configurations, and adapt to node failures, especially when using cheaper preemptible instances.
Solution: Sailor System
Sailor introduces a comprehensive system for automating ML training in the cloud with two main innovations: elastic fault-tolerant mechanisms and an optimal resource planner.

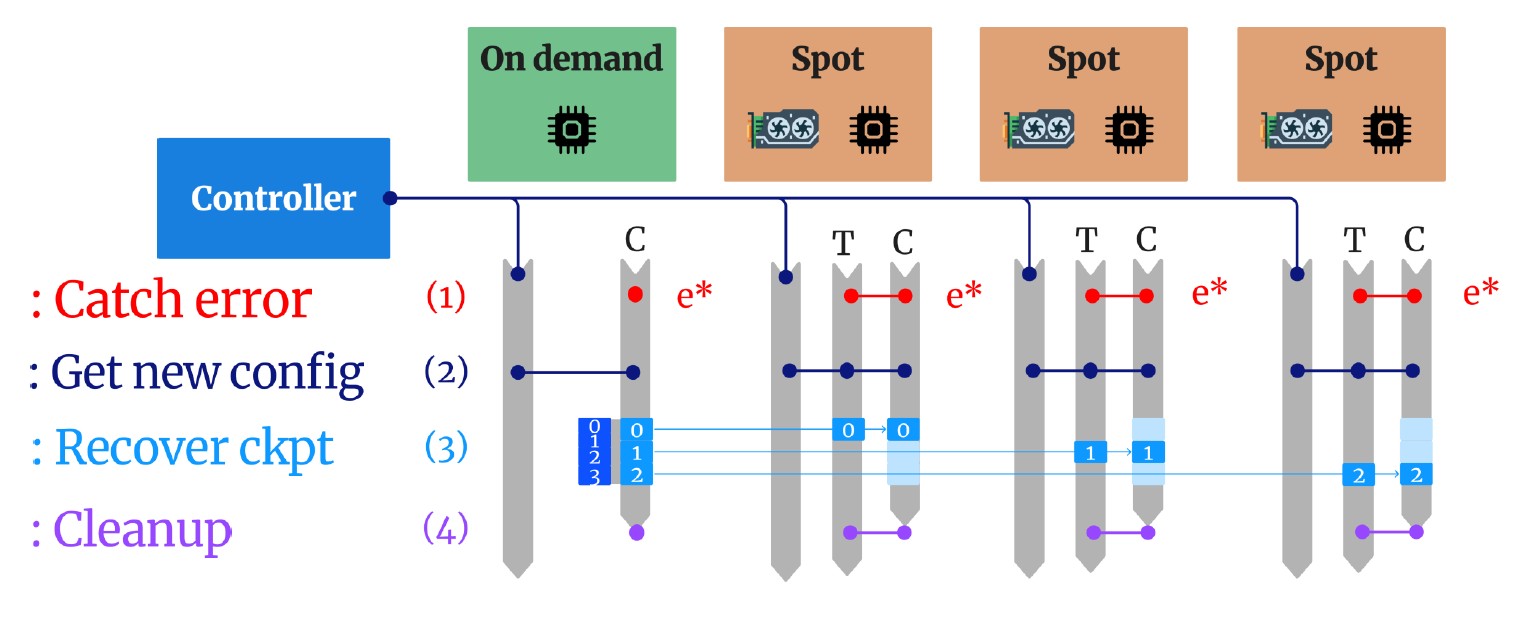
Multi-cluster coordination with master controller
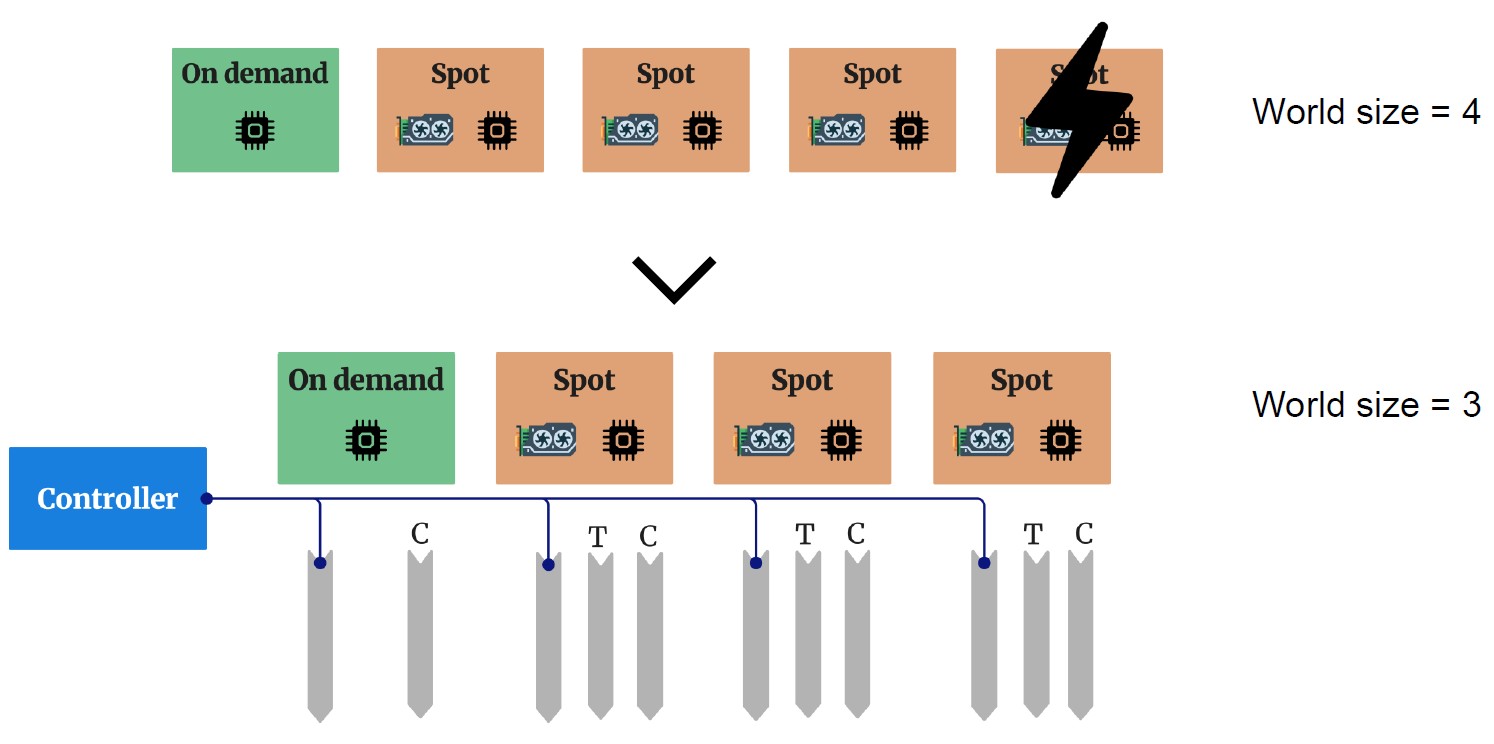
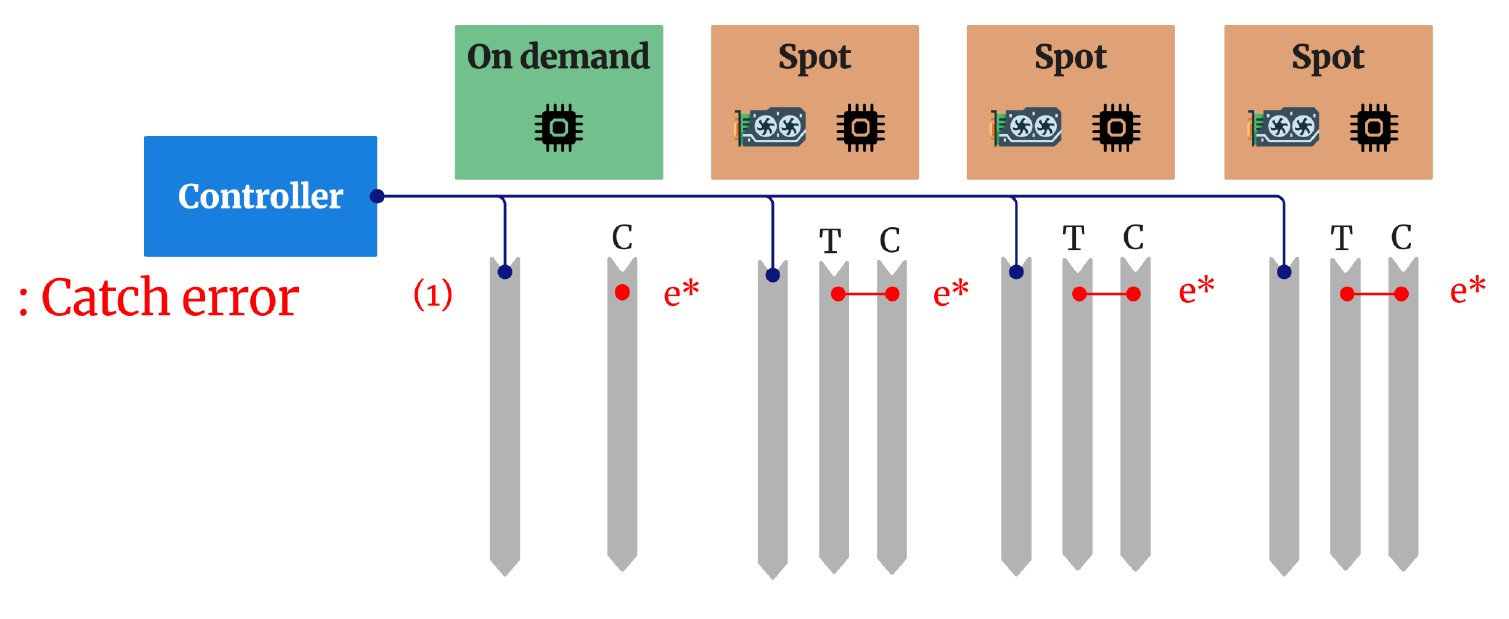
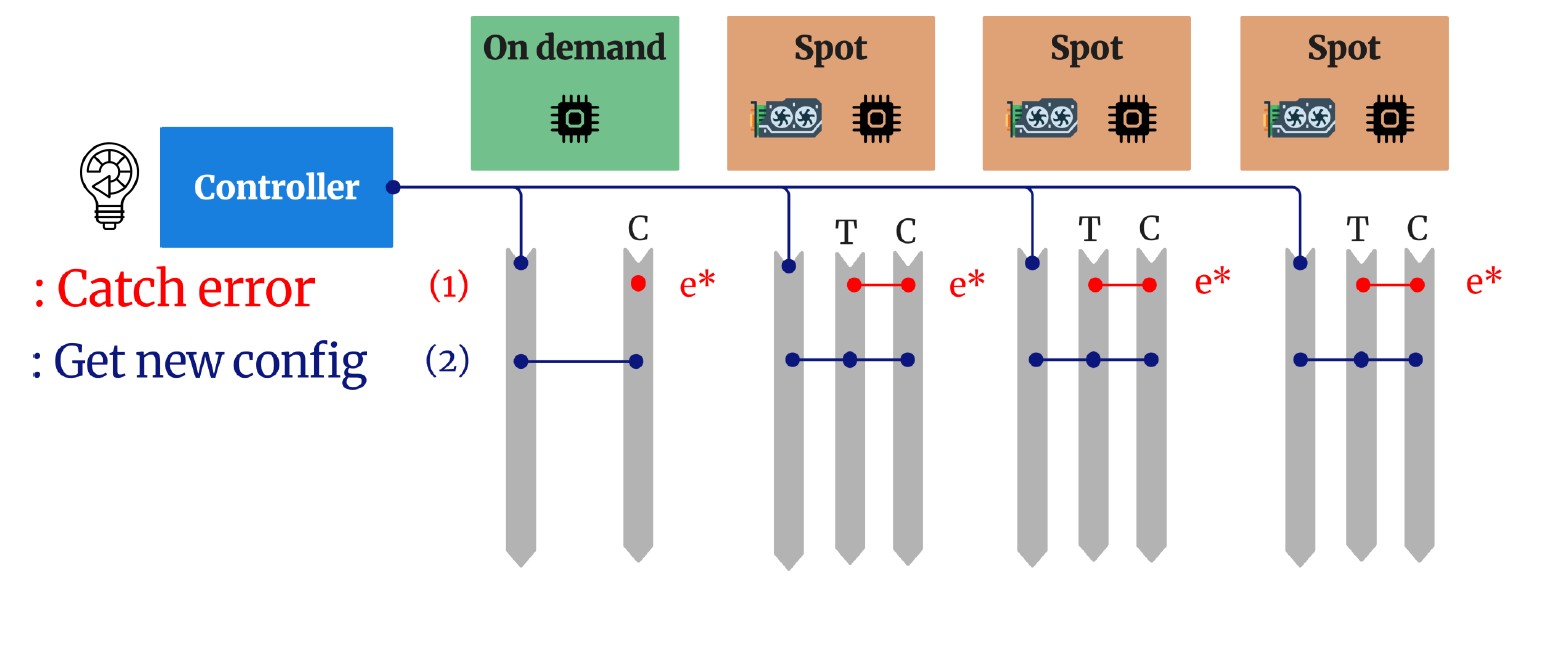
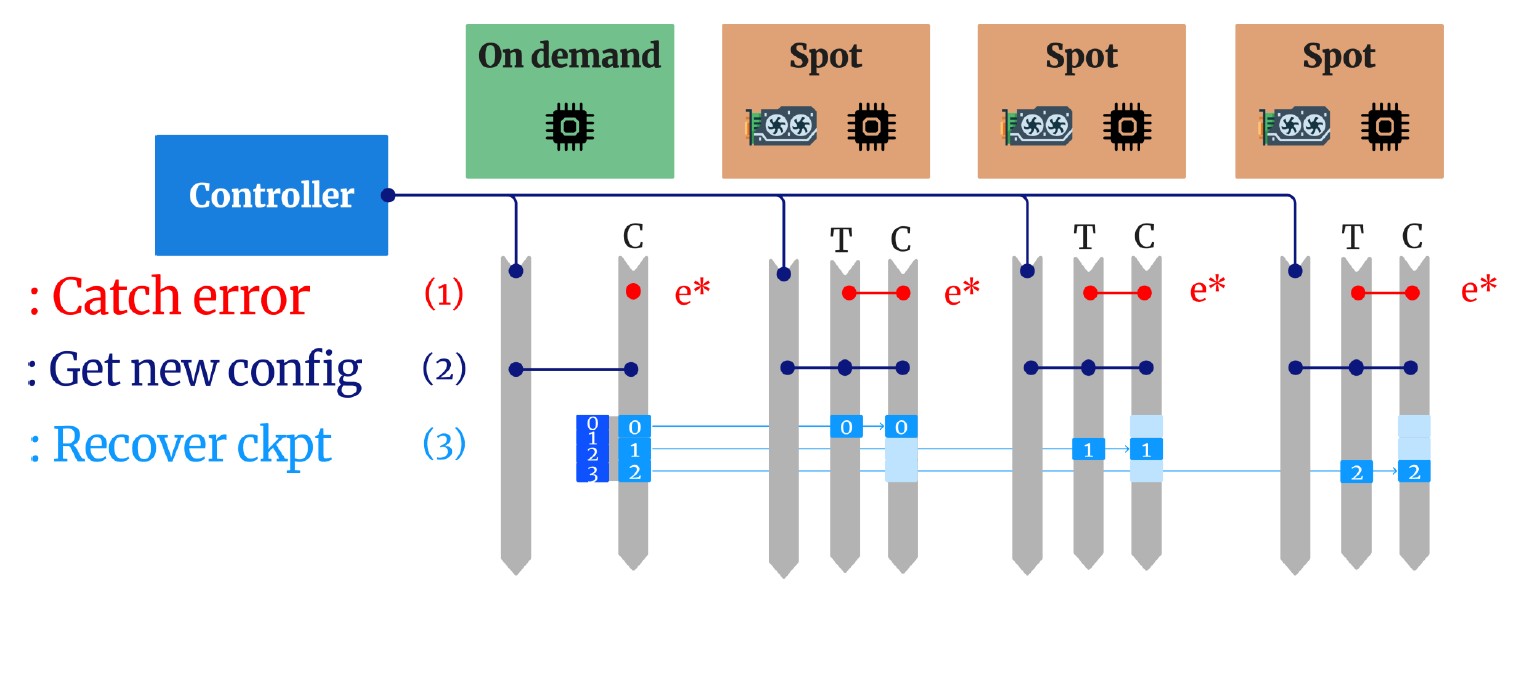
1. Elastic Fault-Tolerant Mechanism
We developed a novel in-CPU checkpointing mechanism that enables fast recovery from failures and preemptions. Unlike traditional approaches that write checkpoints to disk or remote storage, our method:
- Stores checkpoints directly in CPU memory for instant access
- Enables rapid reconfiguration when nodes are preempted or fail
- Minimizes training interruption through elastic scaling
- Adapts dynamically to changing resource availability

2. Optimal Resource Planner
Our optimization algorithm intelligently navigates the cloud resource search space to find the most cost-effective training configurations.
Results & Impact
Our evaluation demonstrates significant improvements over existing approaches:
- 2.87x higher goodput on preemptible VMs compared to state-of-the-art fault tolerance methods
- 100× faster optimization for finding optimal training configurations
- Cost-efficient training of 1.5B+ parameter models using cheaper preemptible instances
- Minimal recovery overhead thanks to in-CPU checkpointing
Real-World Impact
Sailor enables researchers and organizations to train large language models at a fraction of the cost, making advanced ML capabilities more accessible. By efficiently leveraging preemptible VMs, which can be 60-90% cheaper than on-demand instances, the system democratizes access to large-scale ML training.
Open Source
This work has been continued and expanded by the Efficient Architectures and Systems Lab at ETH Zürich. The project is now open source and available on GitHub: